
前面我们讲到hadoop 安装的环境
现在正是安装下hadoop
安装前,我们先进入hadoop用户下面
把下载好的hadoop安装包,放入/home/hadoop2
cp /opt/hadoop-2.7.3.tar.gz /home/hadoop2/
进行解压
tar xzvf hadoop-2.7.3.tar.gz
然后配置hadoop环境变量
vim /etc/profile
export JAVA_HOME=/home/jdk1.8.0_74
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_HOME=/home/hadoop2/hadoop-2.7.3配置完后用 source /etc/profile 执行下让我们配置的环境变量生效
修改hadoop-2.7.3文件的权限
hadoop2代表用户名称
hadoop-2.7.3代表文件夹名称
chown -R hadoop2:hadoop2 /home/hadoop2/hadoop-2.7.3
修改hadoop-env.sh 启动hadoop时需要javaJDK环境,需要修改java_home路径
vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/jdk1.8.0_74
这样我们就部署好单点的hadoop
我们使用 hadoop 命令可以看到启动成功了
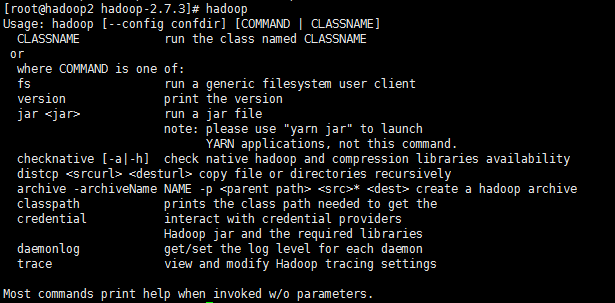
我们使用hadoop fs -ls /
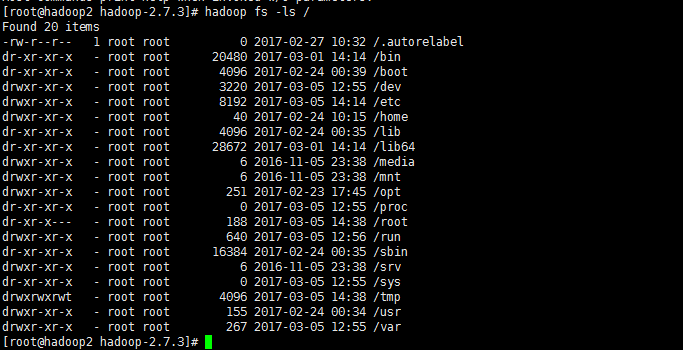
hadoop 会读到根目录 ,因为我们没有配置文件系统,hadoop默认读取的是localhost本地文件系统,现在hadoop 也可以执行文件
我们可以新建一个目录
mkdir inputfile
vim inputfile/test.txt
aaa bbb ccc dd aa
然后执行
hadoop jar /home/hadoop2/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount ./input ./out1
执行成功后我们进入out1目录下面会看到
part-r-00000 这个文件夹
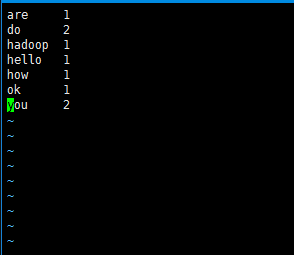
hadoop会帮我们算出用的个数